AI Verticals - Who has the right to play?
When ChatGPT came out in November 2022, OpenAI was actually releasing two things to the general public: (good) LLMs & a chat interface. This obfuscated something really interesting; LLMs were a revolutionary technology, and by releasing ChatGPT, OpenAI had basically entered one vertical: chat.
As the underlying LLM technology has steadily advanced, the verticals have exploded. Today, we have products in all sorts of verticals, including legal, customer service, outbound, marketing content, security, and health. All great businesses that serve real needs.
Far and away, though, the leading vertical has been software engineering. Github Copilot and Cursor quickly entered the arena and took off. In 2023, tab completion became accurate and standard. Then, they began being able to handle tougher and tougher questions. By the end of 2024, Cursor was able to handle complex features all on its own. All of this progress was on the back of constant model improvements from OpenAI and Anthropic. As those frontier models improved, so too did the experience in these IDEs. OpenAI/Anthropic were making money on API use, Cursor was making money on Cursor subscriptions. A happy relationship.
Then something interesting happened: Claude Code came out in early 2025. Suddenly, the lines blurred. A model provider was also providing a harness around coding, directly competing with Cursor, Windsurf, and VSCode + Copilot. Later that year, Cursor responded by building their own model, Composer. OpenAI followed Anthropic into coding with Codex (the model), and more importantly, the Codex App. And Cognition followed Cursor into model-building, with the newly-launched SWE-1.5 and SWE-1.6 models.
The AI Development vertical and the platform are ramming into each other at full speed. Why did this happen in software engineering? Where do other verticals stand? Is there room for other players, or is it the Eye of Sauron when one of these model players gets involved?
Revenues, valuations, and threats
Chasing the valuations
I actually don't aim to do a financial analysis in this blog post, but it's evident that Anthropic and OpenAI have huge valuations at multiples much higher than is considered normal. They need to grow their revenue to support these valuations.
ChatGPT is a household name; they almost certainly have the largest share of chat users and subscribers. And while OpenAI is working on adding advertisements to further monetize their chat product, they're going to need to look for other ways to grow revenue. Public estimates are that 55-75% of their current revenue comes from the chat product, while ~20% comes from API usage.
On the flip side, Anthropics valuation comes off the back of a huge revenue percentage coming from the API (~75%). They have a front-row seat to what sorts of value creation is being done on top of their model layer.
Both companies will be looking outside of their chat product to drive revenue.
Value capture
A few days ago, Anthropic released a tweet that has received a ton of buzz, detailing the usage of the API access they provide for their models:
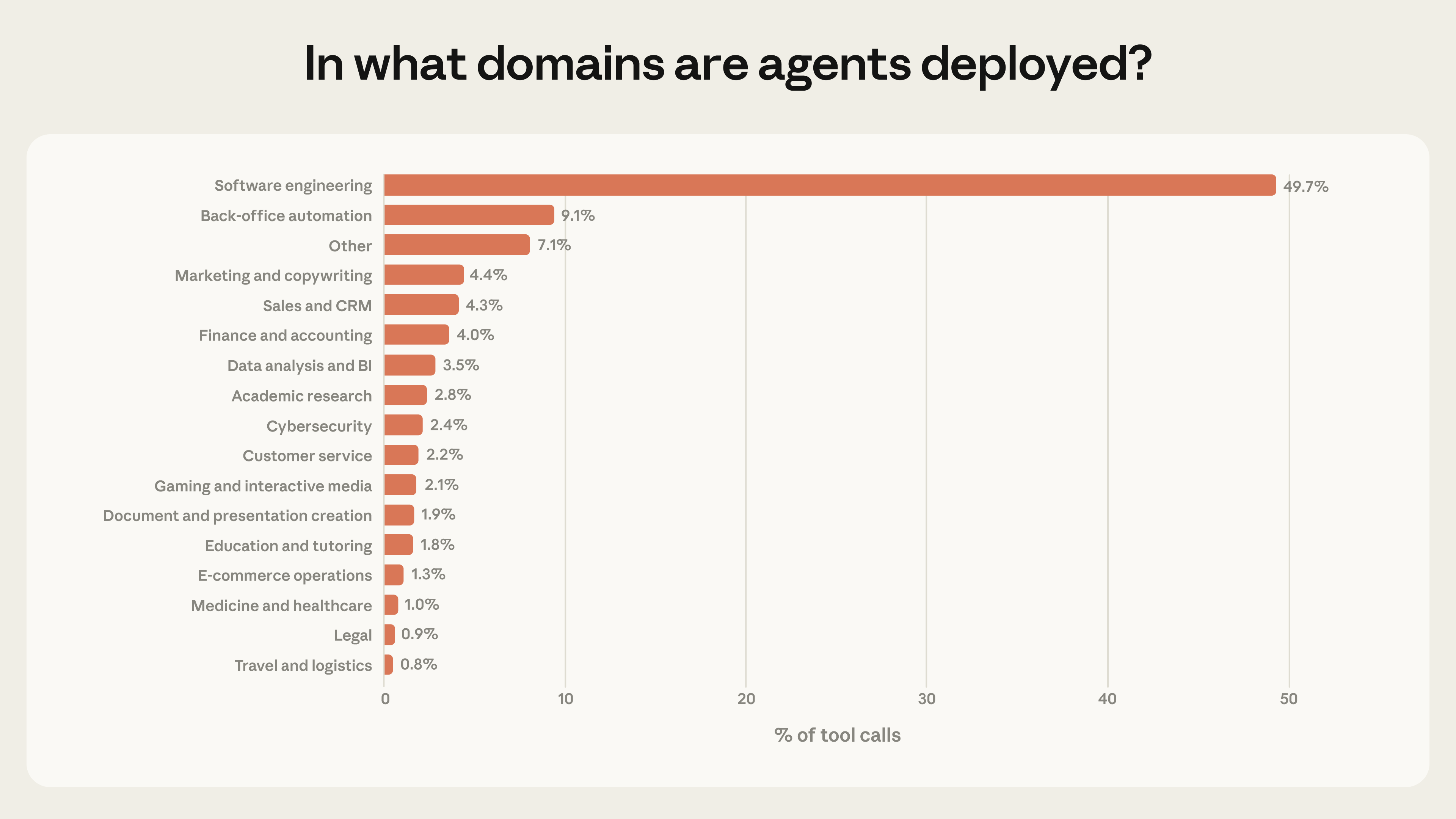
Almost 50% of Anthropic's tool calls are software engineering related. As I understand it, this does not include Claude Code -- this is any software engineering tool supporting Anthropic's models like Opus and Sonnet.
This chart describes perfectly why Anthropic has entered this space. There is so much value being captured by other products that are using Anthropic's APIs in the backend and arbitraging that cost. By building Claude Code, Anthropic is able to capture the value at the harness layer, which was previously flowing to other tools.
Model commodification
By no means do I mean to diminish the progress that the frontier model providers are providing, but it is clear that the usage of models is becoming interchangeable in the software engineering world. This would've been evident as far back as 2023, when Anthropic and OpenAI models started appearing side-by-side in selectors in various apps such as VS Code+Copilot, Cursor, and Windsurf.
Today, you feel that commodification even more viscerally everyday on Twitter. The flavor of the week changes constantly, whether it's switching to the new Opus model, or back to the new Codex model, or a 1 million token context-window Sonnet model.
Open-source models have caught up too. Kimi provides fantastic performance for its cost. We will soon enter an era where frontier models are only needed for complex tasks, and the open-source models will likely be delegated the basic ones. In time, the open-source models may even be good enough for the complex ones.
On the path to AGI
The value of coding models
There's another reason that OpenAI and Anthropic focus so much of their model releases on their coding abilities, and even release families of models that include coding-specific models.
Roughly, the AGI thesis is this:
- Intelligence is expected to hockey-stick as soon as the models are able to autonomously improve themselves.
- Models are trained using code-based systems.
- Once models are good enough, they will be able to improve their own code-based systems for training.
And so, "coding AGI" is roughly equivalent to "AGI", given the former enables the latter. The labs are very incentivized to reach coding AGI.
Collecting data
Let's extend the above thesis:
- Intelligence is expected to hockey-stick as soon as the models are able to autonomously improve themselves.
- Models are trained using code-based systems.
- Once models are good enough, they will be able to improve their own code-based systems for training.
- One of the best ways for coding models to improve is to collect more training data.
- The better the coding harnesses are, the more training data the frontier labs will be able to collect.
Therefore, there is significant incentive for the frontier labs to make their harnesses appealing to users -- the more they have users using their systems, the more data they'll be able to collect to get closer to that hockey-stick of growth.
The battle might be existential
For the model providers
There's clear signs that the shift from proliferation to value capture has begun. Recently, Anthropic clarified their stance on plan-based usage vs api-based usage in their legal docs.
Developers building products or services that interact with Claude’s capabilities, including those using the Agent SDK, should use API key authentication through Claude Console or a supported cloud provider.
Anthropic does not permit third-party developers to offer Claude.ai login or to route requests through Free, Pro, or Max plan credentials on behalf of their users.
Anthropic reserves the right to take measures to enforce these restrictions and may do so without prior notice.
Or in other words: "we're willing to take a loss on users using Claude Code, but not via your product". This effectively cut off the arbitrage that others were taking advantage of: using a user's $200 spend on credits to facilitate $1000s in use. When used in surfaces like OpenClaw, which allowed long-running agents, or multi-agent orchestrators, the bill could run up far into the thousands.
There's a reason this stance was hardened in January 2026. The model providers have high valuation expectations, they have growing usage coming specifically from one segment that's siphoning value away from them, and the threat of easy model-switching + open-source models in 3rd party applications directly affects their bottom-line and growth.
The closer we get to the top of the S-curve, the more open-source is looming. Kimi and Qwen come close on benchmarks already, and fine-tuning brings them even closer. It would be devastating to Anthropic & OpenAI if the industry-leading harness were to shift to a constellation approach that heavily emphasized open-source models. And the best defense of that is to own the harness layer.
For the AI Development applications
The equation is quite straightforward for these players:
- My customers demand the best models.
- The best models are now charging my customers usage-based pricing instead of fixed-cost, even while in my platform.
- This means that my usage-based pricing adds margin to the model providers' usage-based pricing.
- The model providers are rolling out competing development platforms without that added margin.
- My service is now more expensive than directly using the frontier model providers' platforms.
And you see the direct response to this. The biggest players left in the AI Development space (Cursor & Cognition) are both rolling out their own models: Composer & SWE.
Building out research arms is famously expensive. But it's highly necessary for both of these organizations. If the model providers are going to compete on development platforms, the development platforms will have to compete on models.
It's an interesting moment for the industry. We have fine-tuned models that perform better or as well as the frontier models on various benchmarks. It levels the playing field for the AI Development applications to compete against the model providers.
Are other verticals next?
I'm not clairvoyant, by any means, but this is my read.
It is true that any vertical on top of model providers captures value for every dollar spent. It's also true that these businesses may be capturing significant margins over their token usage.
However, I don't believe OpenAI and Anthropic are in the position to really act like the Eye of Sauron. It's important to remember that their valuations don't make them all-encompassing behemoths with unlimited reach. They're actually in a reasonably precarious position still, like any startup, and most of their strategy still hinges on a bid for survival.
The model providers are reasonably concerned (well, some more than others) about the position their data center expenditures put them in. When placing these orders, they're explicitly placing bets on the revenue that they will achieve to be able to pay those orders in the future. Recently, Dario explained that a 20% miss on revenue could mean bankruptcy for Anthropic. Sam Altman had to walk back company comments suggesting a federal backstop would be requested.
These huge datacenter builds are in the service of AGI. Once they've achieved AGI (whatever that means), they believe they will be able to make trillions off model access.
So, I believe this incursion into the AI Development vertical is purely in service of that progress. The labs need to grow revenue to fund datacenter builds that theoretically will create AGI. The house of cards may still come falling down if they can't do it even with those datacenters, but that's the bet.
Given what Anthropic is seeing (50% of tool calls being used for software development), it makes sense for the labs to go after the "biggest fish" in terms of value. So much so that it's worth the distraction/diversion of resources as they build towards AGI. That equation doesn't hold the same weight in other use cases (all <10% of tool calls), so I roughly estimate that they will avoid the incursion.
My thesis: Getting involved with the AI Development vertical is only a means to an end for the research labs. I don't believe their strategy is to subsume all verticals -- it would simply be too distracting and not yield enough value to justify their valuation.